Deep Image Prior
Published:
- 论文链接:https://arxiv.org/abs/1711.10925
- 会议: International Journal of Computer Vision (2020)
- Keywords: CNN, generative deep networks, inverse problems, image restoration
Abstract
这篇论文研究了深度卷积网络在图像生成和修复中的应用。传统上,人们认为深度卷积网络的优秀性能归因于它们从大量示例图像中学习到的现实图像先验。然而,本文作者指出,在某种程度上,生成器网络的结构已经足够捕捉大量的低级图像统计信息,而无需进行任何学习。
为了证明这一点,作者展示了随机初始化的神经网络可以作为手工制作的优秀先验 (a handcrafted prior with excellent),在标准逆问题(如去噪、超分辨率和修复)中取得良好的结果。此外,相同的先验还可以用于反向解析深度神经表示以诊断它们,以及根据闪光和非闪光输入对来恢复图像。
除了其多样的应用之外,本文的方法还突显了标准生成器网络架构所捕捉到的归纳偏见。同时,该方法填补了两个非常受欢迎的图像恢复方法的鸿沟:基于深度卷积网络的学习方法和使用 handcrafted 图像先验(如自相似性)的无监督学习方法。
What is a handcrafted prior?
How to invert deep neural representations to diagnose them?
What is flash-no flash and how to implement it?
How to bridge the gap between two image restoration methods?
1. Introduction
首先指出图像修复问题中的 sota 模型目前 (2020年) 还都是基于 CNN。 *(2023年可能已经是 diffusion model 的天下了)
提出问题:
标签随机化(labels are randomized)时,同样的数据会出现训练过拟合的现象。
要想获得良好的性能,需要网络的结构和数据的结构进行共振(resonate),然而这种相互作用的性质仍然不清楚,尤其是在图像生成领域。
指出本文的工作和创新点:
- 发现了并非所有的图像先验都必须从数据中学习;相反,大量的图像统计信息被 generator ConvNets 捕获,独立于学习
- 证明了上述发现尤其适用于图像修复领域
实验设计
- 将未经训练的 CNN 应用于这类问题的解决
- 将 generator network 应用于单个退化图像
- 网络权值作为复原图像的参数
在这种设计之下,用于执行重建的唯一信息被包含在单个降级的输入图像和用于重建的 handcrafted structure of the network
Re Q1: 单个 Generotor ConvNets 的初始化权重参数
这是第一个在不从图像中学习网络参数的情况下,直接研究深度卷积生成网络捕获的先验信息
实验的进一步推广
2. Method
首先介绍了什么是 deep generator network,即 a parametric function $x = f_{\theta}(Z)$ that maps a code vector z to an image $x$.
接着,表述了人们一般认为关于 $P(x)$ (可以理解为一张图片像素的复杂分布) 的知识是被编码在网络的参数 $\theta$ 中的,因此通过训练大量的数据进行学习,而作者在文中表明:即使没有对模型参数进行任何训练,关于图像分布的大量信息也包含在网络的结构中。 证明了未经训练的网络捕获了自然图像的一些低级统计数据,结合局部和平移不变性质,利用卷积和算子序列等方式捕获多尺度像素领域的关系。利用这一方法对于图像恢复这一类型的图像分布 $P({x}\mid{x_0})$ 进行建模,$x$ 是修复图像,$x_0$ 是待修复图像。
提出目标函数, \(\theta ^ * = \underset{x}{argmin} E(f_\theta (z);x_0) , x^* = f_\theta * (z)\)
- 疑问:
- 论文中说 $E(x;x_0)$ is a task-dependent data term,没有很懂是什么意思,以至于我也没看懂他这个目标函数是啥。
- 现在懂了,$E$ 可以理解为某一特定任务的数学表达方式,而在此处表示:使神经网络训练生成的图像 $x$ 尽可能接近待修复图像 $x_0$
- 名词解释:
- ground truth: 用于监督网络学习的图片,比如在超分任务中, ground truth 指低分辩率图片所对应的高分辨率图片
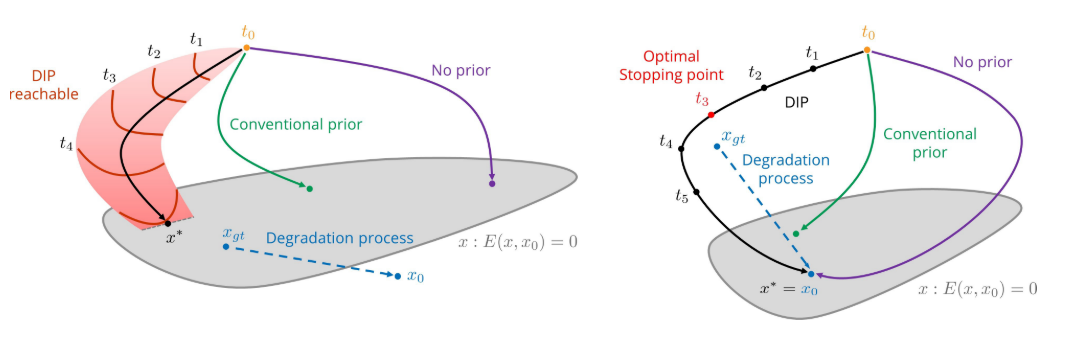
2.1 A parametrization with high noise impedance
详见下方的 6.2.1 and 6.2.2
2.2 “Sampling” from the deep image prior
介绍了实验中如何设计网络结构  * 上图中五列分别代表不同的网络结构,每一列代表两种不同的随机输入$\theta$ * 这张图是神经网络采样阶段的可视化结果 (可以理解为diffusion model 中的扩散阶段,所得到的图片是 reverse 阶段的起点)
* 上图中五列分别代表不同的网络结构,每一列代表两种不同的随机输入$\theta$ * 这张图是神经网络采样阶段的可视化结果 (可以理解为diffusion model 中的扩散阶段,所得到的图片是 reverse 阶段的起点)
3. Applications
- https://dmitryulyanov.github.io/deep_image_prior
3.1 Denoising and generic reconstruction
在前面介绍过,神经网络天生对自然的图像更加敏感,因此非常适合应用于图像去噪的任务当中。 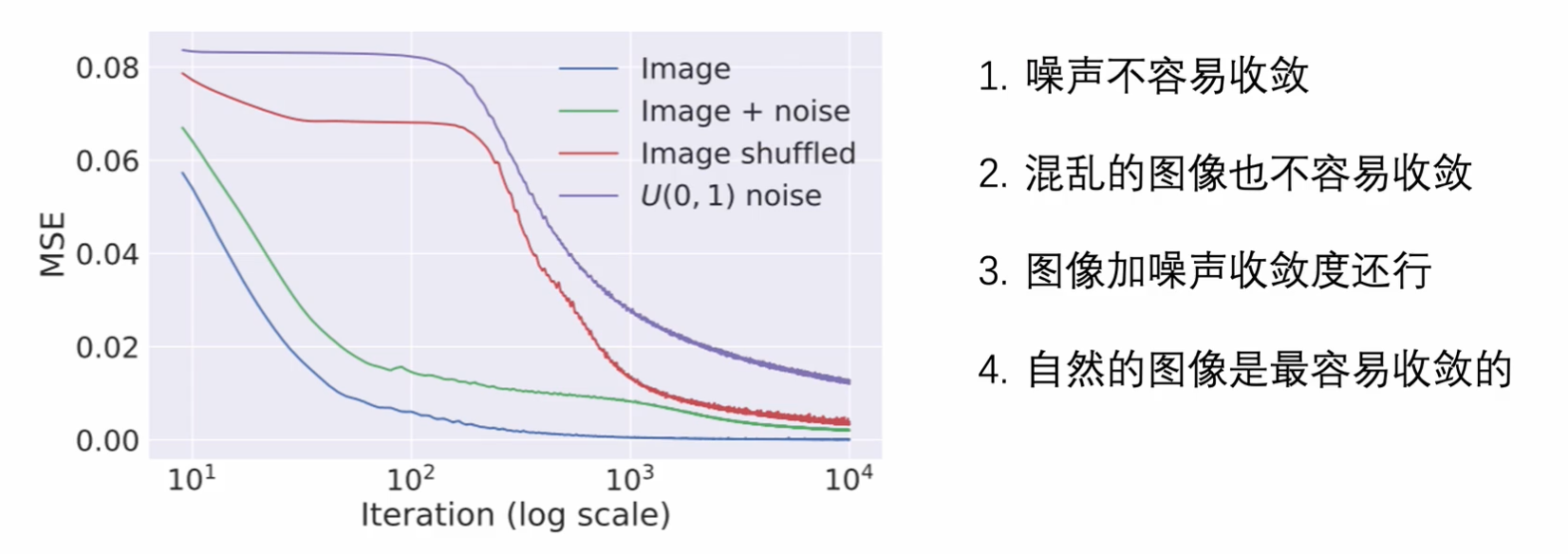
3.2 Super-resolution

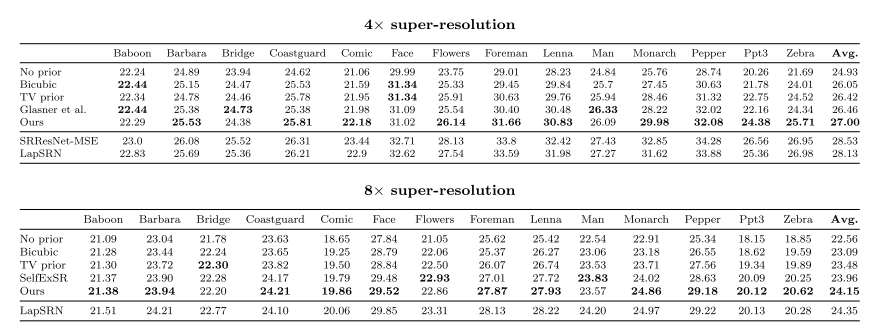
3.3 Inpainting
3.4 Natural pre-image
3.5 Activation maximization
3.6 Image enhancement
3.7 Flash-no flash reconstruction

4. Technical details
这一部分详细介绍了神经网络是如何设计的,如果要深入研究,可结合文章提供的代码重点阅读。 主要包含以下内容:
- 网络架构
- 激活函数的选择
- 优化器的选择
- ……
5. Related work
讲解了与 paper 相关的工作,具体包含以下内容:
- 关于滤波器的相关研究
- 关于利用周边相似像素修补图像的方法
- 介绍了 the zero-shot super-resolution approach
- ConvNets
- ……
6. Discussion
可以改进的地方:
- 实用性有限:对于大多数实际应用场景,这种方法修复图像太慢了
- 可解释性:本篇文章没有解释为为什么神经网络对于自然图像的结构更加敏感,而仅仅是发现了这一现象。
7. 补充 & 理解
7.1 源自知乎的讲解
Deep Image Prior - 高峰OUC的文章 - 知乎 https://zhuanlan.zhihu.com/p/81621716
Deep Image Prior 的重要特点是,网络由始至终仅使用了被破坏过的图像做为训练,没有经历过大多数神经网络所需要的学习过程即可完成任务。 它没有「看过」任何其它图像,也没有看过未受破坏的正常图像,但最终恢复的效果依然很好,这说明自然图像的局部规律和自相似性确实很强。
7.2 源自 B 站的讲解
【组会-深度网络竟然天生就懂得去噪?】 https://www.bilibili.com/video/BV1bB4y1472M/?share_source=copy_web&vd_source=06503cc8285f468251f7ebe06f8e75de
7.2.1 Related work
- 观察上图可得,真实图像在在进行某学习任务中更容易收敛
- Image shuffled (将图像的像素信息随机打乱,使得图像失去空间信息), $U(0,1)$ noise 的变化曲线可能存在神经网络强行拟合的可能性而不是学习任务所需要的规律
7.2.2 Motivation
结合上述内容,可以得到三点动机:
- 神经网络对于噪声和不自然不规律的事物具有抵抗力,很抗拒不自然的图像
- 结合前人的研究发现,,给网络随机打散标签,它会先学习其中有价值的模式
- 那么我们如果让网络直接拟合不自然的图像,能否在中间过程当中出现自然的图像呢?
从上面这些内容,隐约地可以感受到一股扩散模型雏形的味道。
7.2.3 Raise questions
当我们手中只有坏图像,应该如何去修复它们呢?(无监督学习)
作者提出了一个“惊为天人”的方法,如下图所示: 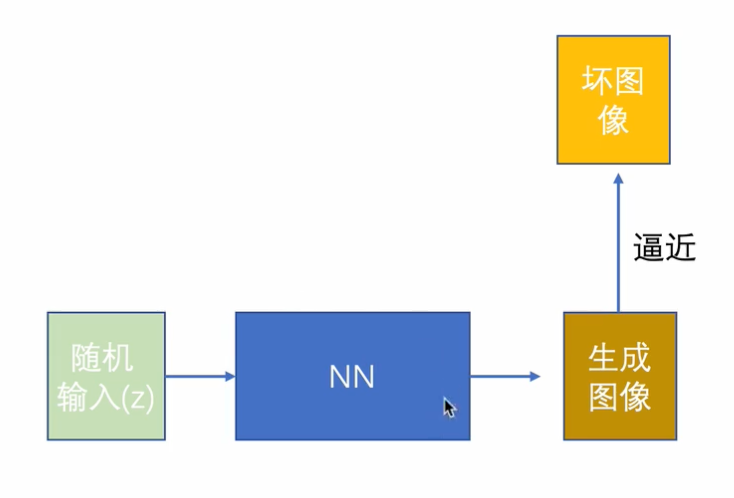
比较神奇的一件事情是,神经网络天生能够理解那些图片是自然的,那些图片是不自然的。
7.2.4 Networks
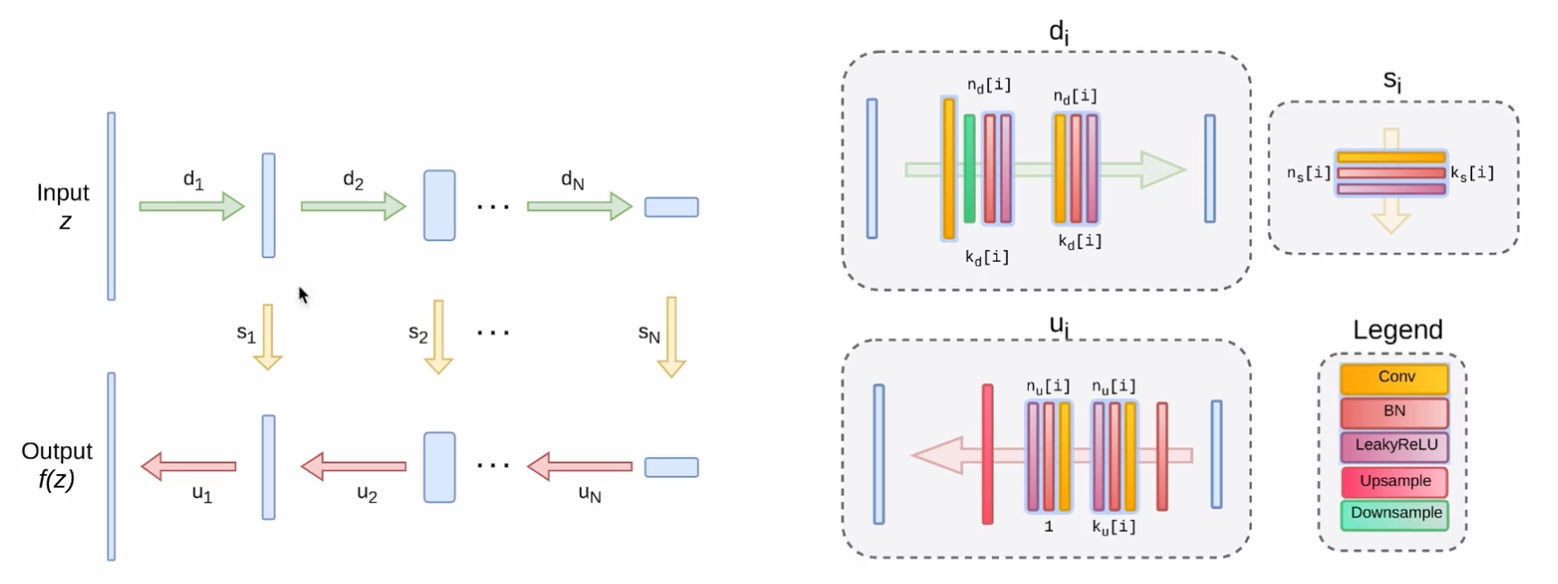
7.2.5 Results
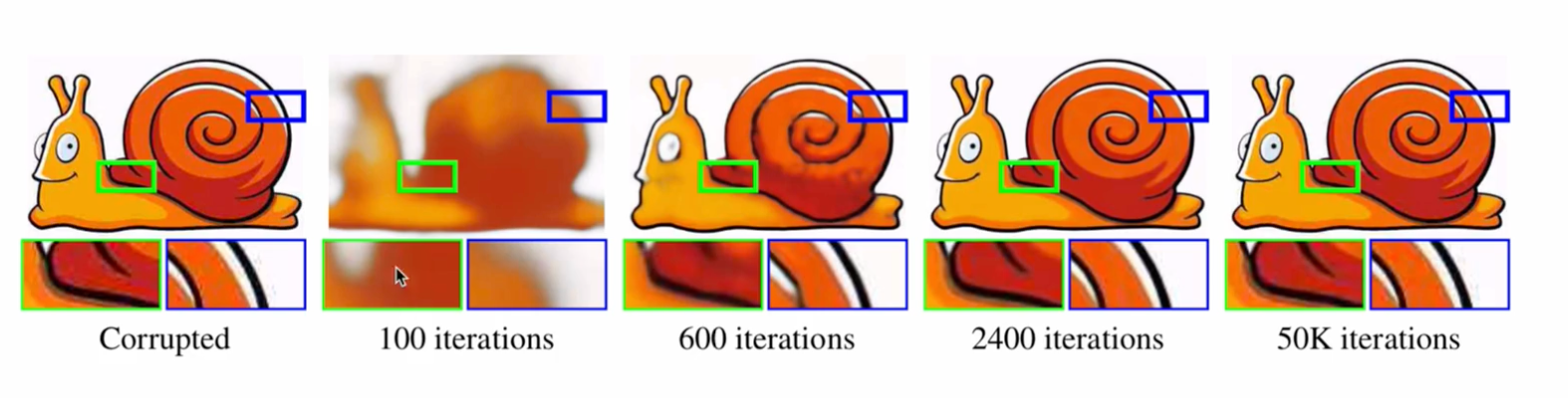
对于上面的去噪任务中,可以看出随着迭代次数的增加,最好的结果出现在了 2400 iterations